HDFS와 MapReduce에 대해 |
您所在的位置:网站首页 › hdfs namenode -format报错文件不可执行 › HDFS와 MapReduce에 대해 |
HDFS와 MapReduce에 대해
|
HDFS와 MapReduce
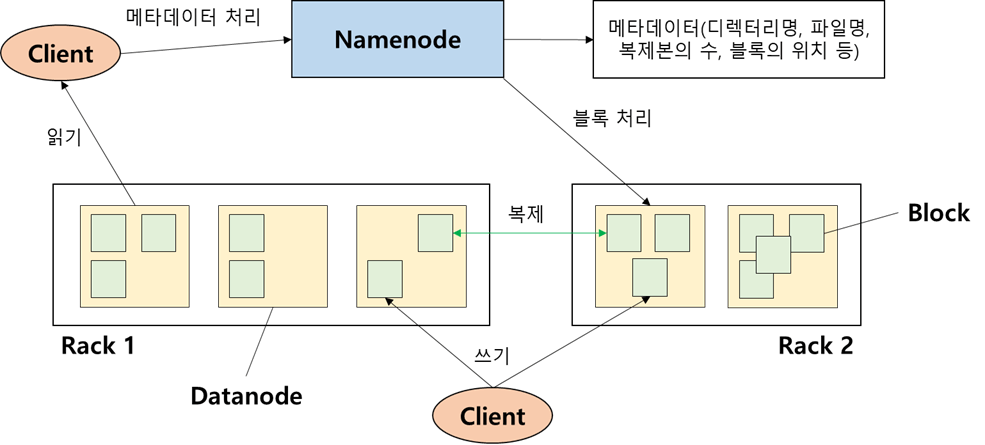
이전 글에서는 Hadoop에 대해 간단하게 알아보았으며, 이번 글에서는 Hadoop의 코어 프로젝트인 HDFS와 MapReduce에 대해 간단히 알아보겠습니다. Hadoop의 버전마다 차이가 있을 수 있습니다.Hadoop 1.x의 경우 블록 크기의 기본값이 64MB지만 Hadoop 2.x의 경우 블록 크기의 기본값은 128MB입니다. ◈ HDFS(Hadoop Distributed Fils System, 분산 파일 시스템) HDFS는 데이터를 여러 서버에 분산하여 저장하는 분산 파일 시스템입니다. 데이터를 블록 단위로 분할하여 여러 서버에 저장하고, 데이터의 안정성과 내고장성을 제공합니다. HDFS에는 마스터/슬레이브(master/slave) 구조로 하나의 네임노드와 여러 개의 데이터노드로 구성됩니다.
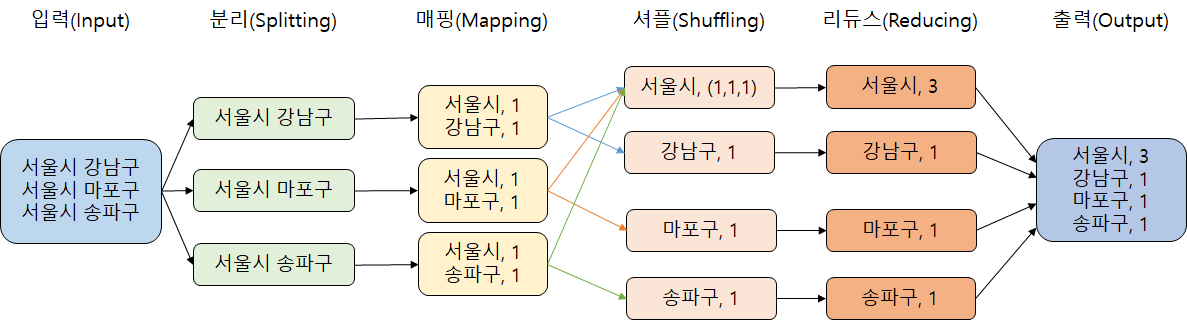
네임노드는 HDFS의 중앙관리자 역할을 수행합니다. 메타데이터를 저장하고, 파일 시스템의 네임스페이스를 관리합니다. 네임노드는 각 파일에 대한 블록의 위치, 파일 및 디렉터리 구조, 사용자 권한 등의 정보를 유지합니다. 또한 데이터노드와의 통신을 통해 데이터의 복제 및 관리를 담당합니다. ◇ Datanode(데이터노드) 데이터노드는 실제 데이터를 저장하는 역할을 합니다. 파일은 하나 이상의 블록으로 분할되며 분할된 블록들이 데이터노드에 저장됩니다. 데이터노드는 네임노드와의 통신을 통해 블록의 보고, 복제, 복구 작업 등을 수행합니다. ◈ MapReduce(분산 데이터 처리 모델)MapReduce는 대규모 데이터를 분산하여 처리하는 프로그래밍 모델로 메모리에 담을 수 있는 작은 블록으로 나누어 처리합니다. 각 블록은 데이터를 처리하는 Map단계를 거쳐 중간 결과를 생성하고, Reduce단계에서 중간 결과를 집계하여 최종 결과를 생성합니다.
MapReduce는 실제 코드 구현이 복잡하고 저수준의 프로그래밍 모델입니다. MapReduce 대신 사용자 친화적이고 간편한 Spark가 있습니다. 함께 보면 좋은 글 Hadoop이란 무엇인가? Hadoop이란 무엇인가? Hadoop(High-Availability Distributed Object-Oriented Platform) Hadoop은 대용량 데이터를 처리하기 위한 오픈소스 프레임워크로, 현재 많은 기업과 조직에서 대용량 데이터 처리에 활용되고 dev-records.tistory.com
|
【本文地址】
今日新闻 |
推荐新闻 |